AWS NLBs and the mixed up TCP connections
One of my services was running into timeouts, because connections were being reset by clients. I had assumed that it couldn’t be the Network Load Balancers (NLBs) fault, a battle-tested piece in the cloud stack. The following is about NLBs, cross-zone-loadbalancing and multiple NLBs pointing to the same set of EC2 instances and how that revealed unexpected behaviour in the NLB.
TLDR: If you don’t want timeouts or connection resets, then:
- don’t use cross-zone loadbalancing
- don’t have multiple NLBs pointing at the same targets
- don’t use a public IPv4 address and an NLB for the same target
Update 05.11.2020: AWS has since gotten in touch with me to discuss this issue and added a section to their troubleshooting guide.
The symptom: Timeouts
My system was doing lots of requests to two NLBs over the internet. Unfortunately in quite some cases there were timeouts in the application code. The timeouts were quite aggressive at 1 second. Since a normal packet loss during connecting usually takes 3 seconds before a retry on linux, I initially explained it away as naturally occurring packet loss. But the number of failures grew ever higher with the link not even close to being saturated and other calls to external targets being fine.
When I finally got myself to take tcpdumps of the traffic, something strange emerged: TCP RST packets.
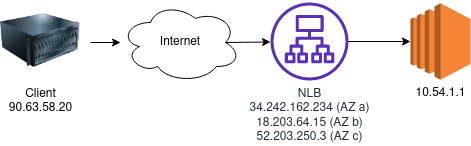
The Setup (simplified)
The configuration in which these issues actually surfaced had multiple machines behind a NAT, talking to multiple EC2 instances behind two NLBs with cross-zone-loadbalancing enabled.
But that’s the messy reality, let’s keep it simple for this article. In the following let’s have 1 client, 1 NLB and 1 EC2 instance, because the issue would still be the same.
The NLB has cross-zone loadbalancing enabled.
Background
In TCP, connections are identified by the quadruple of source ip, source port, target ip and target port. When you create a new TCP connection, it is made sure that no other connection with the same quadruple is in use.
The problem
(Fast forward a couple of days of staring at tcpdump and head-scratching) Here is an excerpt of tcpdump as the client sees it, with all the noise removed:
Format clientip:clientport <-> targetip:targetport (so a bit different than it looks in wireshark)
... This connection has been established for some time
90.63.58.20:36230 <- 34.242.162.234:443 Seq=1234 Ack=5432 [ACK]
EC2 instance (private IP) says through the NLB (34.242.162.234) to the client (90.63.58.20): Hey, I just received your data, all is good. This connection is healthy and sending data. Everything as expected. Now our client wants to make a new connection and sends a SYN packet.
90.63.58.20:36230 -> 18.203.64.15:443 Seq=6951 [SYN]
As you notice, the source ports are identical, but this is fine, as the target IPs are different.
Next in the 3-way handshake of TCP we would expect a [SYN,ACK] with Ack=6952
90.63.58.20:36230 <- 18.203.64.15:443 Seq=1234 Ack=5432 [ACK], window reduced
This packet has the same quadruple, but it isn’t our [SYN,ACK]… wait a sec. Where is this coming from? Does this ack belong on the other connection that the client had with 34.242.162.234!?
The Ack numbers match, but that can’t be, can it?

90.63.58.20:36230 -> 18.203.64.15:443 Seq=5432 [RST]
Well, at least the client is as confused as I am and sends an RST. It just sucks that this means our SYN will never be properly answered.
Is the SYN of the new connection overwriting an existing connection in the NLB’s connection table?
The cause
Since I had so much trust in AWS NLBs I first assumed the issue to lie somewhere (anywhere) else. I imagined it could theoretically be a faulty switch or a misconfigured NAT gateway on the client side. But it turned out to be neither of them. It was actually the AWS NLB mixing up the connections. How can this happen?
Cross AZ-loadbalancing
When the traffic goes through the NLBs the target IP address get rewritten to the internal IP address of the EC2 instance.
Now how would it look from the client if three connections are created in a round-robin fashion?
90.63.58.20:20536;34.242.162.234:443
90.63.58.20:36895;18.203.64.15:443
90.63.58.20:60356;52.203.250.3:443
Now this looks unproblematic, nice quadruples - no RST packets. But what happens if we have more and longer-lived connections? Could collisions happen?
...
90.63.58.20:36230;34.242.162.234:443 let's call this connection A
...
90.63.58.20:36230;18.203.64.15:443 and this one B
...
As I said in the background, the kernel ensures that there are no quadruple collisions. And this is still the case in this case. The same source port can be reused, as long as the target ip or port are different. As the connections go to different IPs of the NLB, this is the case… but only from the view of the client. In the NLB the addresses are translated to an internal IP. So on the EC2 instance the quadruples look like this:
...
90.63.58.20:36230;10.54.1.1:443 A
...
90.63.58.20:36230;10.54.1.1:443 B
...
Now this looks problematic. Two TCP connections share the same quadruple. Thus the NLB cannot distinguish between them and sends the packets on either of them.
Is this a bug?
An ordinary NAT would handle such collisions just fine. When a collision is detected, not only the address is translated but also the port. This makes it possible to handle the complete port range before collisions occur. NLBs apparently don’t act like NATs. I couldn’t find this spelled out anywhere, but apparently they always preserve the source port. This basically means that whenever a client makes more than one connection to the NLB, collisions may occur. During my research I found out I am not the only one irritated by that and that they opened a support ticket and got the confirmation that this is indeed intended behaviour.
In any case I don’t think anyone would derive this from just the docs and TCP knowledge. There should at least be a big warning sign in the documentation.
What to do now?
This issue not only occurs with cross-zone-loadbalancing, but any time two external IPv4-addresses point to the same EC2 instance in AWS. This includes multiple NLBs pointing at the same target or an instance having both a public IPv4 address and being behind an NLB.
What I take away from this is to never have two NLBs pointed at the same target groups as well as to turn cross-az loadbalancing off for most use-cases. And never assume that a part of your stack is infallible.
Discuss on Hacker News or Reddit